FAQ
1 What are 'Reliability', 'Validity' and 'Quality'?
SQP provides information about the quality of survey questions. The quality of a survey question is defined as the strength between (a) the latent concept of interest and (b) the observed response to the measure or survey question. There are at least three sources of measurement error affecting the quality of survey questions: The first one is random error. Random measurement errors are due to unintended and unpredictable mistakes by either the respondents when choosing the right answer, the interviewers when reporting the answer given by the respondent, or the data coders when coding the responses into the database. Thus, if one could ask the same question several times, people would not give the same answer, and the coders would not code the answers the same way. So, the responses of respondents contain random measurement errors.
The second source of measurement error is the way people react to the different ways of formulating a survey question. For example, the response may be different for a question depending on whether a categorical scale with 5 points or an 11-point scale is used because people may react differently to the different formulations. Some respondents usually give extreme answers on an 11-point scale, while others do not use the most extreme responses. Still, both groups of respondents may use the 5-point scale in the same way (Saris and Gallhofer, 2014). This source of measurement error is named method effect or systematic error.
Finally, the third source of measurement error appears when a question does not perfectly cover the concept of interest that is intended to be measured. Imagine measuring the complex concept of “job satisfaction” using the following survey question: “Would you choose the same job if you could choose again?” Although the question probably reflects well the complex concept it intends to assess (namely, respondents’ satisfaction with the current job), they could, for instance, consider in their response not only satisfaction with their current job but also satisfaction with other possible jobs in the past. This suggests a difference, called a unique component, between the complex concept to be measured and the simple concept measured by the question. Figure 1 indicates where these different errors can play a role.
The second source of measurement error is the way people react to the different ways of formulating a survey question. For example, the response may be different for a question depending on whether a categorical scale with 5 points or an 11-point scale is used because people may react differently to the different formulations. Some respondents usually give extreme answers on an 11-point scale, while others do not use the most extreme responses. Still, both groups of respondents may use the 5-point scale in the same way (Saris and Gallhofer, 2014). This source of measurement error is named method effect or systematic error.
Finally, the third source of measurement error appears when a question does not perfectly cover the concept of interest that is intended to be measured. Imagine measuring the complex concept of “job satisfaction” using the following survey question: “Would you choose the same job if you could choose again?” Although the question probably reflects well the complex concept it intends to assess (namely, respondents’ satisfaction with the current job), they could, for instance, consider in their response not only satisfaction with their current job but also satisfaction with other possible jobs in the past. This suggests a difference, called a unique component, between the complex concept to be measured and the simple concept measured by the question. Figure 1 indicates where these different errors can play a role.
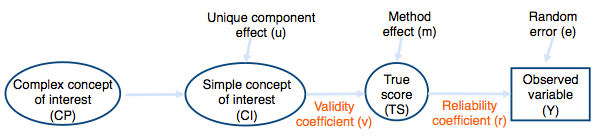
The observed variable (Y) contains the responses to a specific survey question. As illustrated in Figure 1, this observed variable also contains random errors (e). Therefore, the latent true score for this observed variable (TS) can be defined as the observed variable minus the random errors. The strength between the true score and the observed variable is the reliability (r2) of the question. The larger the contribution of the true score to the observed score, the higher the reliability of the question. Reliability can thus be formulated as follows:
Reliability (r2) = 1 – proportion of random error in the observed variance
Because all survey questions are formulated in a specific way, the true score is partially affected by the variable the question is supposed to measure (i.e. the simple concept of interest) and partially by the reaction of the respondents to the method used (i.e. the method effect). In other words, the latent simple concept of interest can be defined as the latent true score minus the method effect, simply called method error variance. The strength between the simple concept of interest and the true score is the validity (v2) of the question. Validity can be formulated as follows:
Validity (v2) = 1 – proportion of method error variance in the true score variance
Up to this point, it could be said that by removing the method effects from the true scores, the scores obtained would represent the concept that the question was supposed to measure. However, as said before, this simple concept may not perfectly represent the complex concept the researcher intends to measure. It may be that these two differ due to unique components. This last part of the measurement process is not considered by SQP's quality prediction. The quality prediction given by SQP only refers to simple concepts. The evaluation of the quality of complex concepts requires more research and analysis (Saris and Gallhofer, 2014 and DeCastellarnau and Saris, 2014).
The above definition of reliability is the same as in the literature in general, but the definition of validity is different because some authors call construct validity the product of SQP's definitions of validity and the reliability (Andrews, 1984). Others define validity as the relationship between the complex concept of interest and the observed variable. In SQP, the terms reliability and validity are used as defined above, and the product of these two is defined as the quality of a survey question.
The above definition of reliability is the same as in the literature in general, but the definition of validity is different because some authors call construct validity the product of SQP's definitions of validity and the reliability (Andrews, 1984). Others define validity as the relationship between the complex concept of interest and the observed variable. In SQP, the terms reliability and validity are used as defined above, and the product of these two is defined as the quality of a survey question.
Quality (q2) = reliability (r2) x validity (v2)
The quality indicators of survey questions (i.e., reliability and validity) are estimated based on Multitrait-Multimethod (MTMM) experiments. In these experiments, different traits (i.e., simple concepts) are measured with different methods (i.e., different formulations of survey questions). The basic model used for the estimation of the relationships between the simple concept of interest, the true score, and the observed variable is presented in Figure 1. The effects between these variables are represented by the reliability coefficient (r) and the validity coefficient (v). When squared, they provide estimates of reliability and validity. For details on the procedures, go to Saris and Gallhofer (2014).
In the quality output of SQP, two different values are given for each measure. The squared values (r2, v2, and q2) represent the predictions of the reliability, validity, and quality, while r, v, and q represent the reliability coefficient, validity coefficient, and quality coefficient.
In this general definition, it is assumed that the variables of interest are continuous. However, the observed variables are often measured in a limited number of categories. If that is the case, reliability is also affected by the so-called categorization errors (Saris, Van Wijk and Scherpenzeel, 1998).In such a case, reliability will be affected by random error and categorization error.
In the quality output of SQP, two different values are given for each measure. The squared values (r2, v2, and q2) represent the predictions of the reliability, validity, and quality, while r, v, and q represent the reliability coefficient, validity coefficient, and quality coefficient.
In this general definition, it is assumed that the variables of interest are continuous. However, the observed variables are often measured in a limited number of categories. If that is the case, reliability is also affected by the so-called categorization errors (Saris, Van Wijk and Scherpenzeel, 1998).In such a case, reliability will be affected by random error and categorization error.
Reliability (r2) = 1 - variance of random and categorization errors
2 What is the distinction between MTMM quality estimates and SQP quality predictions?
In the current SQP database of questions, it can easily be detected whether this information is available or not because of the following icons:
 Indicates that MTMM quality estimate is available
Indicates that MTMM quality estimate is available
 and
and
 Indicate that a SQP quality prediction is available
Indicate that a SQP quality prediction is available
Indicates that MTMM quality estimate is available
and
Indicate that a SQP quality prediction is available
The Multitrait-Multimethod (MTMM) quality estimates are the result of factor analysis of MTMM experiments and are provided in SQP for those questions in the database which were involved in an MTMM experiment.
SQP was developed using a meta-analysis of the results (i.e. quality estimates) of multiple MTMM experiments and the information regarding the characteristics of the questions involved in those experiments (Oberski et al., 2011). Thus, the SQP quality predictions are the result of this meta-analysis and are provided in SQP for the questions in the database for which the characteristics have been coded using the SQP coding system. Moreover, the SQP quality predictions can be provided for any new survey question in the database after coding its characteristics.
In general, the MTMM estimates and SQP quality predictions are quite close (R2 is rather high). However, occasionally the two can differ from each other. Taking into account that the quality estimates obtained through MTMM experiments are the result of a one point in time analysis, and given that the SQP predictions are based on the results of many of these analyses, in general, the SQP quality prediction is a more reliable result than the MTMM estimates. There are only two cases in which reliance on the MTMM estimates over the SQP predictions would be suggested:
SQP was developed using a meta-analysis of the results (i.e. quality estimates) of multiple MTMM experiments and the information regarding the characteristics of the questions involved in those experiments (Oberski et al., 2011). Thus, the SQP quality predictions are the result of this meta-analysis and are provided in SQP for the questions in the database for which the characteristics have been coded using the SQP coding system. Moreover, the SQP quality predictions can be provided for any new survey question in the database after coding its characteristics.
In general, the MTMM estimates and SQP quality predictions are quite close (R2 is rather high). However, occasionally the two can differ from each other. Taking into account that the quality estimates obtained through MTMM experiments are the result of a one point in time analysis, and given that the SQP predictions are based on the results of many of these analyses, in general, the SQP quality prediction is a more reliable result than the MTMM estimates. There are only two cases in which reliance on the MTMM estimates over the SQP predictions would be suggested:
1) Because 'Agree – Disagree' (AD) scales cannot be identified yet in the SQP characteristics (see Limit 4). Thus, although it has been demonstrated that the quality of 'Item-Specific' (IS) scales is much higher than AD scales (Saris et al., 2010), SQP would not be able to distinguish both.
2) The SQP predictions are based on the general trends of the relationships between the different characteristics of the MTMM questions and the MTMM quality estimates of these questions in all countries. Thus, if a question in a country deviates considerably from these general trends the MTMM estimates should be preferred.
3 What is the distinction between 'Authorized predictions' and 'Other user predictions'?
SQP provides 'Authorized predictions', which can be identified by the icon
and the other user predictions, which can be identified by the icon
. This distinction is made to indicate the difference between the results obtained by a controlled and supervised coding procedure and an uncontrolled and unsupervised coding procedure of the characteristics. The 'Authorized predictions' can be trusted because they have been coded in the different languages by native coders under the training and supervision of the SQP team. If the question of interest is coded but not authorized, it is recommended that the coding be checked before using the predictions.
and the other user predictions, which can be identified by the icon
. This distinction is made to indicate the difference between the results obtained by a controlled and supervised coding procedure and an uncontrolled and unsupervised coding procedure of the characteristics. The 'Authorized predictions' can be trusted because they have been coded in the different languages by native coders under the training and supervision of the SQP team. If the question of interest is coded but not authorized, it is recommended that the coding be checked before using the predictions.
4 For which countries is SQP able to provide a quality prediction?
SQP is able to provide quality predictions for the countries involved in the MTMM experiments, since these experiments are the ones used in the meta-analysis. The countries for which the current version of SQP can give a prediction are the following:
Austria, Belgium, Bulgaria, Croatia, Cyprus, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Ireland, Israel, Italy, Latvia, Lithuania, the Netherlands, Norway, Poland, Portugal, Russia, Slovakia, Slovenia, Spain, Sweden, Switzerland, Turkey, Ukraine, United Kingdom and United States.
The basic idea behind SQP is that the quality of a question can be predicted on the basis of the topic of the question, the formulation of the question, the response scale, the mode of data collection, etc. In the formulation of the question, many linguistic characteristics have been included to cope with the language differences. However, these characteristics are not sufficient to cover all differences in qualities across all countries, as estimated in the MTMM experiments. Therefore, a country variable was introduced to cover other effects related to the reaction patterns in the different countries. As a consequence, SQP cannot predict the quality of questions for countries that are not included in the above list.
In other words, from the MTMM estimates included in SQP, only the effect of the country can be identified directly with the selection of the country. The SQP quality predictions include the effect of the language through the effects of the linguistic characteristics. Thus, the SQP quality predictions are available for the above-listed countries in combination with any language (see FAQ 2 for the distinction between MTMM estimates and SQP predictions). For example, supposing users want to study immigration in the Netherlands. For the Spanish immigrants, the Spanish language could be used in combination with the Dutch country. This combination will cover the cultural effect of living in the Netherlands and the linguistic characteristics will capture the effect of the question's language.
It is important to note that the effect of the country variable is in general very small. Therefore, if one wished to obtain a prediction of a question in a country which is not on the list, it would be advisable to choose a 'Prediction country' (see FAQ 5 for the description of 'Prediction country') that is culturally similar to the country of interest.
Austria, Belgium, Bulgaria, Croatia, Cyprus, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Ireland, Israel, Italy, Latvia, Lithuania, the Netherlands, Norway, Poland, Portugal, Russia, Slovakia, Slovenia, Spain, Sweden, Switzerland, Turkey, Ukraine, United Kingdom and United States.
The basic idea behind SQP is that the quality of a question can be predicted on the basis of the topic of the question, the formulation of the question, the response scale, the mode of data collection, etc. In the formulation of the question, many linguistic characteristics have been included to cope with the language differences. However, these characteristics are not sufficient to cover all differences in qualities across all countries, as estimated in the MTMM experiments. Therefore, a country variable was introduced to cover other effects related to the reaction patterns in the different countries. As a consequence, SQP cannot predict the quality of questions for countries that are not included in the above list.
In other words, from the MTMM estimates included in SQP, only the effect of the country can be identified directly with the selection of the country. The SQP quality predictions include the effect of the language through the effects of the linguistic characteristics. Thus, the SQP quality predictions are available for the above-listed countries in combination with any language (see FAQ 2 for the distinction between MTMM estimates and SQP predictions). For example, supposing users want to study immigration in the Netherlands. For the Spanish immigrants, the Spanish language could be used in combination with the Dutch country. This combination will cover the cultural effect of living in the Netherlands and the linguistic characteristics will capture the effect of the question's language.
It is important to note that the effect of the country variable is in general very small. Therefore, if one wished to obtain a prediction of a question in a country which is not on the list, it would be advisable to choose a 'Prediction country' (see FAQ 5 for the description of 'Prediction country') that is culturally similar to the country of interest.
5 What is a 'Prediction country'?
Because SQP is only able to give a quality prediction for those countries which were included in the meta-analysis (see FAQ 4 for the list of countries), the current version of SQP provides the possibility, for those countries for which a prediction will not be available, to select a second country that will be used to compute the quality prediction. This is called the 'Prediction country'. This feature allows an approximate prediction of the quality of the survey question to be obtained, even though it is formulated for a country for which a prediction is not available.
This is possible because the effect of the country variable is marginal. Thus, if the country users would like to analyse is not on the list of FAQ 4, it is suggested that a 'Prediction country' be selected which is the most similar in terms of cultural characteristics. In that case, one should also take into account the fact that the amount of uncertainty regarding the correctness of the predictions increases. Thus, if possible, it is recommended trying out different countries. For example, for a country like Canada, there are several countries for the list in FAQ 4 that could be used; United States, Ireland and United Kingdom could be used for those English-speaking questions, while France, Belgium and Switzerland could be used for those French-speaking questions. The decision will depend on whether the 'Prediction country' is most similar in terms of cultural characteristics to the Canadian sample population. Users would have to introduce the question for each country, because by only changing the name of the country of the survey question, users would not obtain a different prediction (see Limit 2).
In the SQP database of questions, it can easily be detected whether a 'Prediction country' has been used to obtain a prediction by the following icon:
 Indicates that a 'Prediction country' has been used
Indicates that a 'Prediction country' has been used
This is possible because the effect of the country variable is marginal. Thus, if the country users would like to analyse is not on the list of FAQ 4, it is suggested that a 'Prediction country' be selected which is the most similar in terms of cultural characteristics. In that case, one should also take into account the fact that the amount of uncertainty regarding the correctness of the predictions increases. Thus, if possible, it is recommended trying out different countries. For example, for a country like Canada, there are several countries for the list in FAQ 4 that could be used; United States, Ireland and United Kingdom could be used for those English-speaking questions, while France, Belgium and Switzerland could be used for those French-speaking questions. The decision will depend on whether the 'Prediction country' is most similar in terms of cultural characteristics to the Canadian sample population. Users would have to introduce the question for each country, because by only changing the name of the country of the survey question, users would not obtain a different prediction (see Limit 2).
In the SQP database of questions, it can easily be detected whether a 'Prediction country' has been used to obtain a prediction by the following icon:
Indicates that a 'Prediction country' has been used6 Which texts should be present in SQP?
In the current version of SQP, only the texts that are read to or by the respondent should be presented. Thus, such texts include the 'Introduction' (if used), the 'Request for an answer' and the 'Answer options'. This implies that all instructions to the interviewer, or everything which is not read to or by the respondent, should not be introduced in the SQP text. Whenever a respondent instruction is used, this text should be introduced in the box 'Request for an answer'.
However, some characteristics will require identifying the extra information during the coding process (e.g. interviewer instructions, use of showcards, showcard layout, don't know option, etcâ¦). Therefore, the coding should be done having the real questionnaire at hand to detect the characteristics that cannot be identified by the SQP text.
However, some characteristics will require identifying the extra information during the coding process (e.g. interviewer instructions, use of showcards, showcard layout, don't know option, etcâ¦). Therefore, the coding should be done having the real questionnaire at hand to detect the characteristics that cannot be identified by the SQP text.
7 How does SQP treat batteries of questions?
SQP has a special way of treating batteries of questions. A question battery consists of a set of stimuli or statements that need to be evaluated by the respondent and have a common request for an answer and the same answer options. In SQP, the request for an answer and, if applicable, the introduction will be placed before the first stimulus or statement in the battery. A stimulus can be a noun or a combination of nouns (e.g., a party name, a name of an institution, or a brand), while a statement consists of a complete sentence. The coder must reflect on how the text of a question battery is read to or read by the respondent and code each item accordingly.
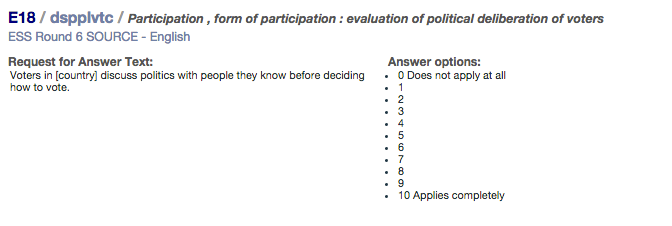
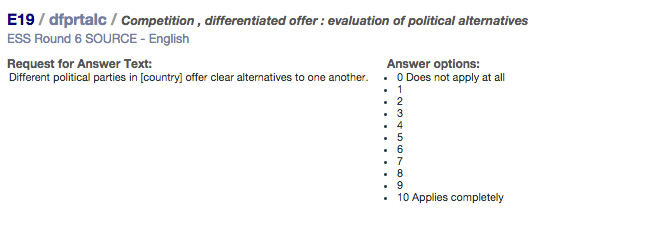
Below is an example of a battery from the ESS Round 6. In this questionnaire, items E17 to E19 asked about the democracy in the country using the following battery of questions:
Below is an example of a battery from the ESS Round 6. In this questionnaire, items E17 to E19 asked about the democracy in the country using the following battery of questions:
"Now some questions on the same topics, but this time about how you think democracy is working in [country] today. Again, there are no right or wrong answers, so please just tell me what you think.
Using this card, please tell me to what extent you think each of the following statements applies in [country]. 0 means you think the statement does not apply at all and 10 means you think it applies completely.
| Does not apply at all | Applies completely | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| E17 National elections in [country] are free and fair | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| E18 Voters in [country] discuss with people they know before deciding how to vote | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| E19 Different political parties in [country] offer clear alternatives to one another | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
This battery is introduced in SQP in the way the interviewer reads the battery to the respondent. That is: (1) the introduction, (2) the request for an answer, and (3) the first statement. These texts together form the first question the respondent has to answer. Next, the second statement is read to the respondent, and the respondent gives an answer. And finally, the third statement is read out. For all the statements following the first one, the introduction and the request for an answer are not repeated. Consequently, these questions only consist of the stimulus or statement.
Thus, the battery should be added to SQP as indicated below, even when it is self-completed (i.e., an interviewer is not reading the questions).
Thus, the battery should be added to SQP as indicated below, even when it is self-completed (i.e., an interviewer is not reading the questions).

This way of introducing the question into SQP matters for coding the characteristics 'formulation of the request for an answer' and 'use of stimulus or statement in the request.'
Following the example, it should be indicated that question E17 is formulated as an indirect request ("Using this card, please tell me to what extent you think each of the following statements applies in [country]...") with a stimulus or statement present ("National elections in [country] are free and fair") preceded by an introduction. However, questions E18 and E19 are coded as having 'no request present' (for the characteristic 'formulation of the request for an answer') but a stimulus or statement (i.e., E18 = "Voters in [country] discuss politics with people they know before deciding how to vote"; E19 = "Different political parties in [country] offer clear alternatives in one another").
Following the example, it should be indicated that question E17 is formulated as an indirect request ("Using this card, please tell me to what extent you think each of the following statements applies in [country]...") with a stimulus or statement present ("National elections in [country] are free and fair") preceded by an introduction. However, questions E18 and E19 are coded as having 'no request present' (for the characteristic 'formulation of the request for an answer') but a stimulus or statement (i.e., E18 = "Voters in [country] discuss politics with people they know before deciding how to vote"; E19 = "Different political parties in [country] offer clear alternatives in one another").
8 Should the 'Don't know' option be counted as a category?
No, the 'Don't know' option should not be treated as a category in the answer options. Thus, it does not have to be counted in the characteristic 'Number of categories' and should never appear in the SQP answer text box. However, this does not mean it is not coded in SQP.
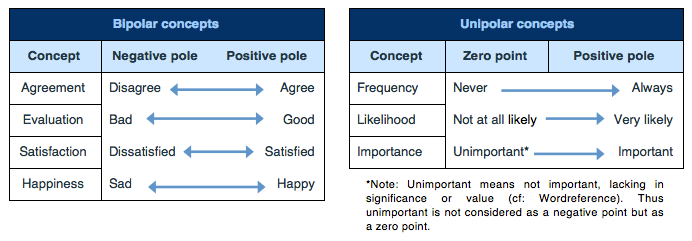
9 What does Bipolarity and Unipolarity mean?
What are theoretically Bipolar and Unipolar concepts?
The concept (i.e. the variable of interest) to be measured can be either bipolar or unipolar. Bipolar concepts have two theoretical opposite poles (e.g. positive/negative or active/passive), while unipolar concepts have only one theoretical pole. Below are examples of bipolar and unipolar concepts in English.
The bipolarity or unipolarity of a concept is language specific. The same concepts can be expressed in the different languages either as bipolar or unipolar concepts. Thus, bipolar concepts in one language may not be translatable as such in other languages.
The polarity of a concept has to be coded in SQP using the characteristic 'Theoretical range of the scale bipolar/ unipolar'.
In order to transform theoretically bipolar or unipolar concepts into survey questions, a request for an answer and a response scale has to be developed. In theory, bipolar concepts can be measured by both bipolar and unipolar requests and scales, while theoretically unipolar concepts can only be measured by unipolar requests and scales.
Often survey questions are measured using complex concepts which combine two basic concepts. Examples of these are:
The first example is composed of the concepts 'Agreement' and 'Policy'. While agreements are theoretically bipolar concepts, the norm regarding what the government should or should not do is theoretically unipolar. Similarly, in the second example the request is composed of an agreement with regard to a feeling. In such cases where the concept 'Agreement' has the main role in the request, users should indicate in SQP that the concept is theoretically bipolar.
Complex concepts can also be composed as in the third example. In that case, both concepts of 'Likelihood' and the 'Future expectation' of employment status are theoretically unipolar. Similarly, because the main role in the question comes from the concept 'Likelihood', users should identify in SQP that the concept is theoretically unipolar.
The polarity of a concept has to be coded in SQP using the characteristic 'Theoretical range of the scale bipolar/ unipolar'.
In order to transform theoretically bipolar or unipolar concepts into survey questions, a request for an answer and a response scale has to be developed. In theory, bipolar concepts can be measured by both bipolar and unipolar requests and scales, while theoretically unipolar concepts can only be measured by unipolar requests and scales.
Often survey questions are measured using complex concepts which combine two basic concepts. Examples of these are:
1. "To what extent do you agree or disagree with the statement: The government should take measures to reduce differences in income levels".
2. "How far do you agree or disagree with the statement: I generally feel that what I do in my life is valuable and worthwhile".
3. "How likely is it that you become unemployed in the next 12 months?"
The words in bold in the examples highlight the complex concept, respectively: an agreement regarding a policy, an agreement regarding a feeling and the likelihood regarding a future expectation.
The first example is composed of the concepts 'Agreement' and 'Policy'. While agreements are theoretically bipolar concepts, the norm regarding what the government should or should not do is theoretically unipolar. Similarly, in the second example the request is composed of an agreement with regard to a feeling. In such cases where the concept 'Agreement' has the main role in the request, users should indicate in SQP that the concept is theoretically bipolar.
Complex concepts can also be composed as in the third example. In that case, both concepts of 'Likelihood' and the 'Future expectation' of employment status are theoretically unipolar. Similarly, because the main role in the question comes from the concept 'Likelihood', users should identify in SQP that the concept is theoretically unipolar.
What are Bipolar and Unipolar requests?
The differentiation between bipolar and unipolar requests will matter for the SQP coding of the characteristic 'Balance of the request'. A theoretically bipolar concept is characterized by the existence of two opposite poles. Thus, if a bipolar concept is formulated in a request for an answer using the two opposite poles of the concept, the range used in the request for an answer is also considered bipolar. For example:
Because the concept "satisfaction" is bipolar and the request also used both possible poles, this request will be considered 'Balanced'.
However, theoretically bipolar concepts can also be formulated as unipolar requests, if only one of the poles is used in the request for an answer.
In this case, because the request will lead the answer to one of the poles when both are available, it should be considered as 'Unbalanced'.
A theoretically unipolar concept is characterized by the existence of only one pole. Thus, as a unipolar concept can only be formulated in a request for an answer using the unique theoretical pole of the concept, the range used in the request for an answer (i.e. the balance of the request) is also considered unipolar. For example:
When the concept measured is unipolar, the balance of the request does not apply, and thus it should be considered as 'Not applicable'.
Bipolar concept: satisfaction
Bipolar request: "How satisfied or dissatisfied are you with the present state of the economy in your country?"
Because the concept "satisfaction" is bipolar and the request also used both possible poles, this request will be considered 'Balanced'.
However, theoretically bipolar concepts can also be formulated as unipolar requests, if only one of the poles is used in the request for an answer.
Unipolar request: "How satisfied are you with the present state of the economy in your country?"
In this case, because the request will lead the answer to one of the poles when both are available, it should be considered as 'Unbalanced'.
A theoretically unipolar concept is characterized by the existence of only one pole. Thus, as a unipolar concept can only be formulated in a request for an answer using the unique theoretical pole of the concept, the range used in the request for an answer (i.e. the balance of the request) is also considered unipolar. For example:
Unipolar concept: importance
Unipolar request: "How important do you think being able to speak English should be in deciding whether someone born, brought up and living outside Great Britain should be able to come and live here?
When the concept measured is unipolar, the balance of the request does not apply, and thus it should be considered as 'Not applicable'.
What are Bipolar and Unipolar scales?
Scales in agreement with bipolar requests and bipolar concepts should measure two poles: positive to negative or active to passive. For example:
However, theoretically bipolar concepts and requests can also be formulated using unipolar scales, if only one of the poles is used in the response scale.
Besides, theoretically unipolar concepts have just one pole and the scales go from zero to positive or from zero to negative.
Bipolar concept: satisfaction
Bipolar request: "How satisfied or dissatisfied are you with the present state of the economy in your country?"
Bipolar scale:
1. Extremely dissatisfied
2. Dissatisfied
3. Neither satisfied nor dissatisfied
4. Satisfied
5. Extremely satisfied
However, theoretically bipolar concepts and requests can also be formulated using unipolar scales, if only one of the poles is used in the response scale.
Unipolar request: "How satisfied are you with the present state of the economy in your country?"
Unipolar scale:
1. Not at all satisfied
2. Fairly satisfied
3. Very satisfied
4. Extremely satisfied
Besides, theoretically unipolar concepts have just one pole and the scales go from zero to positive or from zero to negative.
Unipolar concept: importance
Unipolar request: "How important do you think being able to speak English should be in deciding whether someone born, brought up and living outside Great Britain should be able to come and live here?
Unipolar scale:
0. Not at all important 1. 2. 3. 4. 5. 6. Extremely important
10 How should a question with several steps be coded?
Response scales with several steps are usually measurement procedures consisting of two or more requests and answer scales. For example take the following set of questions:
Following this example, the variable to be measured is a combination of Q2 and Q3, Q1 being a filter question. In SQP, these questions will need to be coded as one, as they intend to measure a unique variable of interest "attitudes towards abortion" and cannot be analysed separately. In order to group the three questions into a unique question, Q1 has to be considered an introduction and Q2 and Q3, the two requests for an answer. However, to code the formal and linguistic characteristics of the request for an answer as 'Bipolarity or Unipolarity', 'Emphasis', 'Encouragement', 'Number of words', one of the two requests, which usually has similar characteristics, needs to be chosen to be presented in the SQP text. Thus, the text to be entered in SQP will be as follows:
(Because people will only get Q2 or Q3, just one of them needs to be put into the text box)
The formal characteristics of the request for an answer will be coded as usual. However, in order to code the answer options' characteristics, it should be indicated in the characteristic 'Response scale: basic choice' the option: 'More step procedures'. In the following characteristics regarding the response scale, the total number of categories, the order of the labels, the correspondence and other characteristics of the scale should be indicated.
To take into account the fact that Q1, a question which is indicated as an introduction, should be coded as a 'Request is present' in the characteristics regarding the introduction.
Furthermore, the linguistic characteristics of the request for an answer should not be the total of the 2 requests but rather only one should be used or an average of the two, if they are different. In the example, both statements have 6 words, 9 syllables, etc.
Q1 "Do you favour or oppose abortion?
1. Favour go to Q2
2. Oppose go to Q3
Q2 "How far do you favour abortion?
1. I am completely in favour
2. I am in favour
Q3 "How far do you oppose abortion?
1. I am completely opposed
2. I am opposed
Following this example, the variable to be measured is a combination of Q2 and Q3, Q1 being a filter question. In SQP, these questions will need to be coded as one, as they intend to measure a unique variable of interest "attitudes towards abortion" and cannot be analysed separately. In order to group the three questions into a unique question, Q1 has to be considered an introduction and Q2 and Q3, the two requests for an answer. However, to code the formal and linguistic characteristics of the request for an answer as 'Bipolarity or Unipolarity', 'Emphasis', 'Encouragement', 'Number of words', one of the two requests, which usually has similar characteristics, needs to be chosen to be presented in the SQP text. Thus, the text to be entered in SQP will be as follows:
Introduction box: Do you favour or oppose abortion?
Request for an answer text box: 1. How far do you favour abortion?
(Because people will only get Q2 or Q3, just one of them needs to be put into the text box)
Answer options box:
1. I am completely in favour
2. I am infavour
3. I am opposed
4. I am completely opposed
The formal characteristics of the request for an answer will be coded as usual. However, in order to code the answer options' characteristics, it should be indicated in the characteristic 'Response scale: basic choice' the option: 'More step procedures'. In the following characteristics regarding the response scale, the total number of categories, the order of the labels, the correspondence and other characteristics of the scale should be indicated.
To take into account the fact that Q1, a question which is indicated as an introduction, should be coded as a 'Request is present' in the characteristics regarding the introduction.
Furthermore, the linguistic characteristics of the request for an answer should not be the total of the 2 requests but rather only one should be used or an average of the two, if they are different. In the example, both statements have 6 words, 9 syllables, etc.
11 References
Andrews, F. M. (1984). Construct Validity and error components of survey measures: structural equation approach. Public Opinion Quarterly, 48, pp. 409-442.
DeCastellarnau, A. and Saris, W. E. (2014). A simple procedure to correct for measurement errors in survey research. European Social Survey Education Net (ESS EduNet). Available at: http://essedunet.nsd.uib.no/cms/topics/measurement/
Oberski, D., Gruner, T. and Saris, W. E. (2011). The prediction procedure of the quality of the questions based on the present data base of questions. In: The development of the program SQP 2.0 for the prediction of the quality of survey questions. RECSM Working Paper 24, 71 - 88. Available at: http://www.upf.edu/survey/_pdf/RECSM_wp024.pdf
Saris, W. E. and Gallhofer, I. N. (2014). Design, evaluation and analysis of questionnaires for survey research. Second Edition. Hoboken, Wiley.
Saris, W. E., Revilla, M., Krosnick, J. A., and Shaeffer, E. M. (2010). Comparing Questions with Agree/Disagree Response Options to Questions with Construct-Specific Response Options. Survey Research Methods, 4(1): 61-79. Available at: https://ojs.ub.uni-konstanz.de/srm/article/view/2682
Saris, W. E., Van Wijk, T. and Scherpenzeel, A. (1998). Validity and reliability of subjective social indicators. Social indicators Research, 45, 173-199.
DeCastellarnau, A. and Saris, W. E. (2014). A simple procedure to correct for measurement errors in survey research. European Social Survey Education Net (ESS EduNet). Available at: http://essedunet.nsd.uib.no/cms/topics/measurement/
Oberski, D., Gruner, T. and Saris, W. E. (2011). The prediction procedure of the quality of the questions based on the present data base of questions. In: The development of the program SQP 2.0 for the prediction of the quality of survey questions. RECSM Working Paper 24, 71 - 88. Available at: http://www.upf.edu/survey/_pdf/RECSM_wp024.pdf
Saris, W. E. and Gallhofer, I. N. (2014). Design, evaluation and analysis of questionnaires for survey research. Second Edition. Hoboken, Wiley.
Saris, W. E., Revilla, M., Krosnick, J. A., and Shaeffer, E. M. (2010). Comparing Questions with Agree/Disagree Response Options to Questions with Construct-Specific Response Options. Survey Research Methods, 4(1): 61-79. Available at: https://ojs.ub.uni-konstanz.de/srm/article/view/2682
Saris, W. E., Van Wijk, T. and Scherpenzeel, A. (1998). Validity and reliability of subjective social indicators. Social indicators Research, 45, 173-199.